
Imagine an office where every single task — answering the phone, filing routine paperwork, and setting five-year corporate strategy — was handed to the most senior, most expensive executive in the entire building. You'd go bankrupt paying that salary against trivial work, and simultaneously the work would crawl, because one overqualified person can't be the bottleneck for everything.
And yet that is exactly what happens when every AI request in your organization gets routed to the same frontier model by default. It's why the model router is about to become standard, non-negotiable infrastructure — the same way load balancers became standard once we stopped pointing all traffic at a single server.
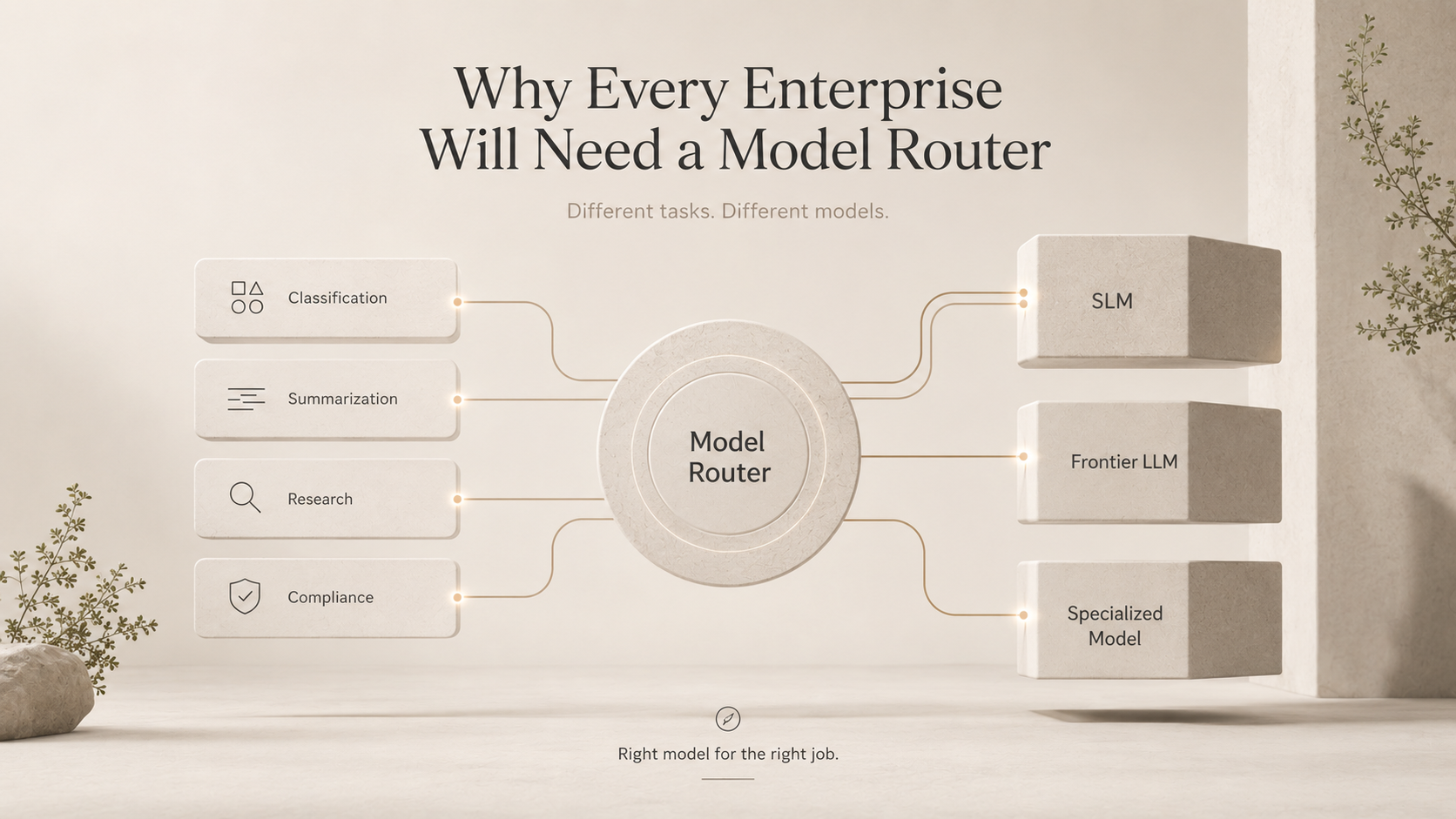
The core idea is almost embarrassingly simple: different tasks should go to different models, matched to the difficulty of the work. Classification → SLM. Summarization → SLM. Research → Frontier LLM. Compliance → Specialized Model.
How a Model Router Works
A model router sits between your application and your fleet of models. It inspects each incoming request — what kind of task is this, how complex, how sensitive, how latency-critical — and dispatches it to the right model for that specific job, rather than reflexively sending everything to the biggest and most expensive option.
The Benefits Compound
The Maturity Move
The single-model era was a phase — the natural simplicity of getting started, not a destination anyone should want to stay at. The mature, durable pattern is a portfolio of models with intelligent routing in front of them.
Before long, 'which model are you using?' will sound exactly as quaint as 'which physical server is your app running on?' The answer will be: it depends on the request, and the router decides.